GLDF: Non-Homogeneous Causal Graph Discovery
This is the reference implementation (github repo) of the framework described by [RR25] for causal graph discovery on non-homogeneous data.
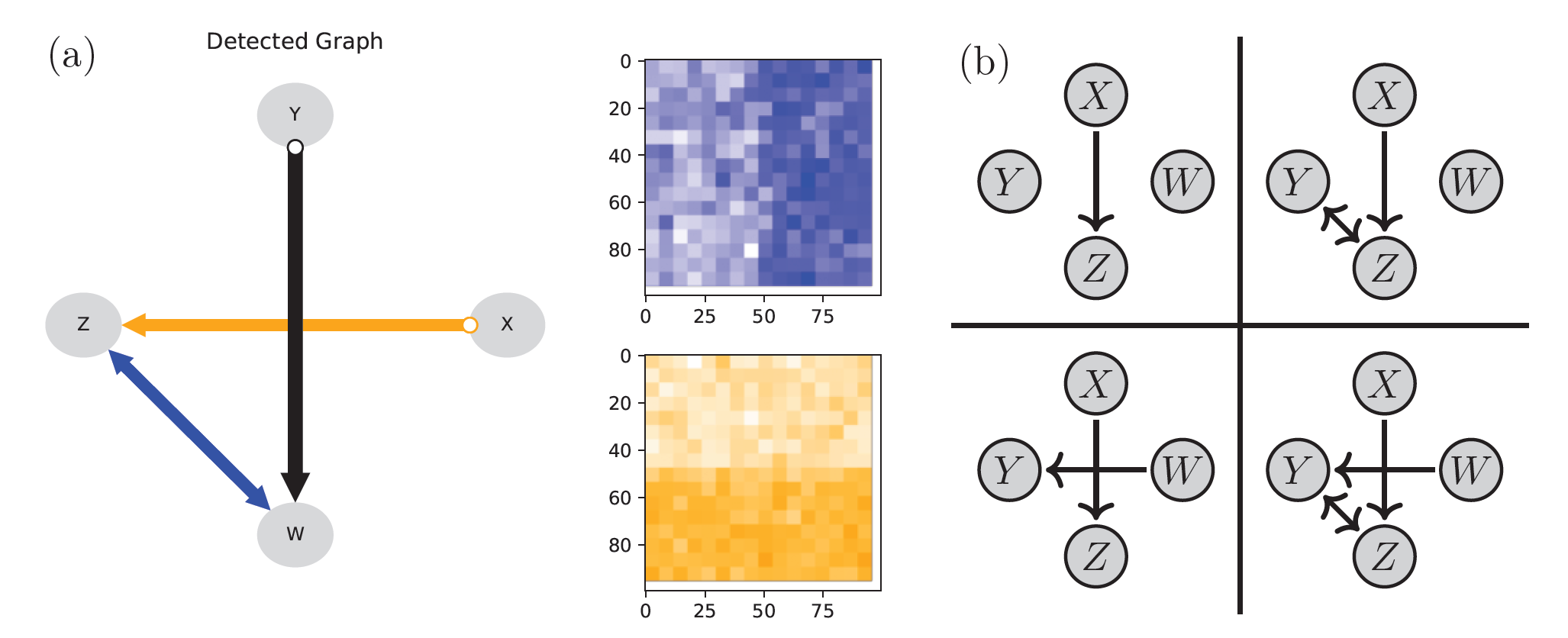
[RR25], Fig. 1.1: On the left-hand side (a), the framework’s output is shown (see tutorial 1 below). Primary focus so far is the (labeled/colored) graph on the very left. The right-hand side (b) illustrates, how the model is described by different causal graphs in different regions of space.
Introduction
Algorithms for causal graph discovery (CD) on IID or stationary data are readily available. However, real-world data rarely is IID or stationary. This framework particularly aims to find ways in which a causal graph changes over time, space or patterns in other extraneous information attached to data. It does so by focusing on an approach that is local in the graph (gL) and testing qualitative questions directly (D), hence the name gLD-framework (GLDF).
Besides statistical efficiency, another major strength of this approach is its modularity. This allows the present framework to directly build on existing CD-algorithm implementations. At the same time, almost arbitrary “patterns” generalizing persistence in time or space can be leveraged to account for regime-structure. The framework extensively builds on modified conditional independence tests (CITs), where individual (or all) modifications can easily be customized if the need arises.
Getting Started
The framework works with many algorithms from the tigramite and causal-learn python packages out of the box. We recommend the user to install at least one of these.
Installation
The package can currently be installed through pip or by cloning the code-repository. Installation via pip should typically occur within a virtual environment, see e.g. venv.
Recommended. Install relevant/helpful dependencies (see Dependencies).
pip install 'GLDF[full]'
The tutorials, provided as jupyter notebooks, additionally require juypter:
pip install ipykernel jupyter
Install only minimal dependencies (see Dependencies).
pip install 'GLDF[minimal]'
Note
Currently pip install GLDF also installs the minimal version,
with PEP 771, if adopted,
we may change the default behavior
to the recommended (full) setting in future versions. To enforce a minimal
setup you should thus not rely on pip’s current fallback behavior.
This package (as any other package) can be installed without pulling in depedendencies
via the --no-deps option:
pip install GLDF --no-deps
Dependencies
Beyond python (version 3.10 or newer, tested on 3.13.5) and the python standard-library, this package requires:
numpy (version 2.0.0 or newer, tested on 2.3.2)
scipy (version 1.10.0 or newer, tested on 1.16.1)
For easy and direct access to plotting functionality:
matplotlib (version 3.7.0 or newer, tested on 3.10.5)
tigramite (version 5.2.0.0 or newer, tested on 5.2.8.2)
networkx (version 3.0 or newer, tested on 3.5)
For easy and direct access to causal discovery algorithms:
tigramite (time-series algorithms; version see above)
causal-learn (IID algorithms; tested on version 0.1.4.3)
Usage
If data is a numpy array of shape \((N, k)\) for \(k\) variables
and a sample-size of \(N\), then
a simple analysis assuming time-series data and persistent in time regimes
can be run out of the box using run_hccd_temporal_regimes as follows:
import GLDF
result = GLDF.run_hccd_temporal_regimes(data)
The result is structured as python object (see frontend.Result)
with easy-to-use visualization and inspection functionality.
Let’s say \(k=4\) and the variables should be labeled \(X, Y, Z, W\)
in the plot (not providing variable names will use indices instead),
then for example the method
plot_labeled_union_graph
produces a plot of the labeled union-graph:
import matplotlib.pyplot as plt
result.var_names = ["X", "Y", "Z", "W"]
result.plot_labeled_union_graph()
plt.show()
Similarly, the individual model-indicators (changing links) can be further inspected as
model_indicators,
for example via the method plot_resolution:
for mi in result.model_indicators():
mi.plot_resolution()
plt.show()
See also the tutorials below for a more detailed start.
Tutorials
We provide short tutorials on the use and customization of our framework in the form of jupyter-notebooks:
Quickstart: Using preconfigured setups for time-series or 2D spatial data.
Detailed Configuration: Change modules, their parameters and other aspects of a setup.
Custom Patterns: A quick intro describing the definition of user-defined patterns.
The tutorials assume the full Dependencies are available (including matplotlib, tigramite and causal-learn).
Overview
This documentation and the framework are divided into two main parts:
The backend contains code implementing functionality required for the framework in a modular way. The documentation of the backend in particular contains detailed information on what features are implemented where and how to customize individual modules. This typically includes a specification of each given (sub-)component in the form of a documented interface (following the naming convention of starting with a capital ‘I’ for interface followed by a verb expressing what the component generally does). The backend is primarily of interest to the user who wants to substantially customize and extend the functionality of the framework itself.
The frontend contains code that satisfies simple user-queries by assembling backend-components in a suitable way. The frontend is primariy of interest to the user who wants to interact with the features provided by the framework in a simple way through higher level (non-modular) tasks, like end-to-end analysis of provided data.
Frontend
Backend
Bridges
Roadmap
Features currently under consideration for future versions. If you want to contribute or have suggestions for improvements, feel free to use github’s features or contact us directly.
Systematic unit-testing, also for simple sanity-checking of custom implementations.
Allow marked tests to “mark” for aspects other than “independent regimes”, e.g. heterogeneity (which is already tested anyway), and aggregate per link results (e.g. consider the link heterogeneous, if all tests on the link [for all conditioning sets] are reported heterogeneous)
Prepare for easier and (computationally and statistically) efficient integration of non-linear tests.
Integrate with JCI/CD-NOD like arguments for obtaining additional orientation information.
Make state-space-construction more robust for large models by exploiting graphical constraints.
Extend post-processing for statistically more meaningful indicator-resolution (potentially including confidence-assessment).
Citation
Please cite as:
@article{rabel2025context,
title={Context-Specific Causal Graph Discovery with Unobserved Contexts:
Non-Stationarity, Regimes and Spatio-Temporal Patterns},
author={Rabel, Martin and Runge, Jakob},
journal={arXiv preprint arXiv:2511.21537},
year={2025},
url={https://arxiv.org/abs/2511.21537},
doi={10.48550/arXiv.2511.21537}
}
Literature
M. Rabel, J. Runge. Context-Specific Causal Graph Discovery with Unobserved Contexts: Non-Stationarity, Regimes and Spatio-Temporal Patterns. archive preprint arXiv:2511.21537, 2025.
J. Runge, P. Nowack, M. Kretschmer, S. Flaxman, D. Sejdinovic. Detecting and quantifying causal associations in large nonlinear time series datasets. Sci. Adv. 5, eaau4996, 2019.
J. Runge. Discovering contemporaneous and lagged causal relations in autocorrelated nonlinear time series datasets. Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence, UAI 2020, Toronto, Canada, 2019, AUAI Press, 2020.
A. Gerhardus, J. Runge. High-recall causal discovery for autocorrelated time series with latent confounders. Advances in Neural Information Processing Systems 33, 2020.
P. Spirtes, C. Glymour, and R. Scheines. Causation, prediction, and search. MIT press, 2001.
P. Spirtes, C. Glymour. An algorithm for fast recovery of sparse causal graphs. Social Science Computer Review, 9:62–72, 1991.
D. Colombo, M. H. Maathuis, et al. Order-independent constraint-based causal structure learning. J. Mach. Learn. Res., 15(1):3741–3782, 2014.
Y. Zheng, B. Huang, W. Chen, J. Ramsey, M. Gong, R. Cai, S. Shimizu, P. Spirtes, and K. Zhang. Causal-learn: Causal discovery in python. Journal of Machine Learning Research, 25(60):1–8, 2024.
License
Copyright (C) 2025-2026 Martin Rabel
GNU General Public License v3.0
See license-file in the code-repository for full text.
This package is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) any later version. This package is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.